Home > Noticias > Actualidad > Machine Learning y nuestra época de estudiantes
NOTICIAS
Actualidad
Actualidad (15 Dic 2020)
Machine Learning y nuestra época de estudiantes
 Jaime de la Serna, Consultor Analista Senior en Analytical Tribe - Grupo eCUSTOMER, recorre con rigor uno de los conceptos claves en Machine Learning: overfitting y underfitting.
Jaime de la Serna, Consultor Analista Senior en Analytical Tribe - Grupo eCUSTOMER, recorre con rigor uno de los conceptos claves en Machine Learning: overfitting y underfitting.
Overfitting y underfitting en Machine Learning: Un recordatorio de nuestra etapa de estudiante
¿Quién no ha escuchado nunca la frase “a una Red Neuronal la alimentas con muchos datos y esta es capaz de resolver una tarea determinada porque al final lo que hace es memorizar esos ejemplos”? Sorprendentemente hoy en día aún existen personas que así lo piensan, aunque generalmente por desconocimiento. Sin embargo, esta cuestión es de suma importancia porque detrás de esto se esconde uno de los conceptos más importantes del Machine Learning.
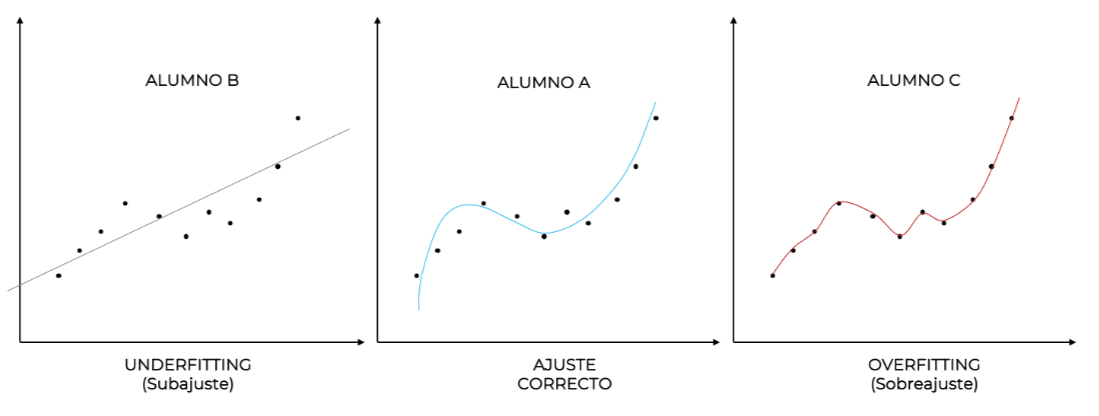
 Volvamos al colegio y hagamos una analogía con eso que seguramente ocurría en tu clase. Normalmente existían 3 perfiles de estudiantes: Alumno A, el aprendiz, aquel alumno que hace un esfuerzo por comprender aquello que se le está diciendo; Alumno B, el estudiante que sin esforzarse mucho tampoco terminaba de aprender bien los conceptos que se veían en clase y su rendimiento no era del todo bueno; Alumno C, el estudiante que no se esforzaba mucho por aprender en profundidad, pero se preparaba muy bien aquello que pensaba que iba a caer en el examen, ya sea memorizándolo o haciendo trampas (copiándolo). Como seguramente te sientas identificado con alguno de ellos, entonces podrás responder a la siguiente pregunta: ¿si hiciéramos un examen qué tal lo haría cada uno? Lo más probable es que el alumno A sacara una buena nota en el examen, notable probablemente, pues ha hecho el esfuerzo de entender en profundidad todo el temario y no tendría dificultad para resolver los problemas que se le plantearan en el examen. El alumno B haría su mejor esfuerzo, pero al no haber adquirido los conocimientos necesarios, probablemente suspendería. Por último, el alumno C, a pesar de no haber asentado ni comprendido en profundidad los conceptos, ha sido capaz de memorizar y/o copiar aquello que se preguntaba y por ello sacará buena nota, incluso mejor que la del alumno A. Pero, más allá de la nota del examen, ¿realmente son iguales los alumnos A y C?
Volvamos al colegio y hagamos una analogía con eso que seguramente ocurría en tu clase. Normalmente existían 3 perfiles de estudiantes: Alumno A, el aprendiz, aquel alumno que hace un esfuerzo por comprender aquello que se le está diciendo; Alumno B, el estudiante que sin esforzarse mucho tampoco terminaba de aprender bien los conceptos que se veían en clase y su rendimiento no era del todo bueno; Alumno C, el estudiante que no se esforzaba mucho por aprender en profundidad, pero se preparaba muy bien aquello que pensaba que iba a caer en el examen, ya sea memorizándolo o haciendo trampas (copiándolo). Como seguramente te sientas identificado con alguno de ellos, entonces podrás responder a la siguiente pregunta: ¿si hiciéramos un examen qué tal lo haría cada uno? Lo más probable es que el alumno A sacara una buena nota en el examen, notable probablemente, pues ha hecho el esfuerzo de entender en profundidad todo el temario y no tendría dificultad para resolver los problemas que se le plantearan en el examen. El alumno B haría su mejor esfuerzo, pero al no haber adquirido los conocimientos necesarios, probablemente suspendería. Por último, el alumno C, a pesar de no haber asentado ni comprendido en profundidad los conceptos, ha sido capaz de memorizar y/o copiar aquello que se preguntaba y por ello sacará buena nota, incluso mejor que la del alumno A. Pero, más allá de la nota del examen, ¿realmente son iguales los alumnos A y C?
Si en un futuro ambos estudiantes tuviesen que enfrentarse a nuevos problemas de ese tema, pero diferentes a los vistos en clase, ¿en quién depositarías tu confianza? Quiero suponer que en el estudiante A, porque su capacidad resolutiva es fruto de un verdadero aprendizaje y, aunque ambos hayan demostrado capacidad para resolver problemas ya vistos, cuando aparezcan nuevos problemas nunca antes vistos pero relacionadas con el tema aprendido, el alumno A será infinitamente más capaz de resolverlos debido a que ha entendido la lógica subyacente de la materia. Es decir, será capaz de generalizar su conocimiento.
Esta generalización es la característica más perseguida en el campo del Machine Learning, porque nos da igual si el modelo es capaz de determinar de manera precisa, sobre los datos utilizados para entrenar el modelo, qué clientes se van a dar de baja. Lo que realmente nos interesa es que el modelo, a partir de los datos de entrenamiento, sea capaz de clasificar o hacer predicciones sobre casos nuevos, nunca antes vistos durante la fase de entrenamiento.
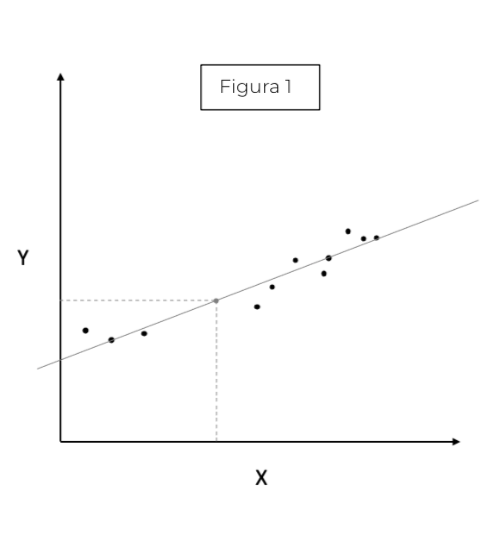
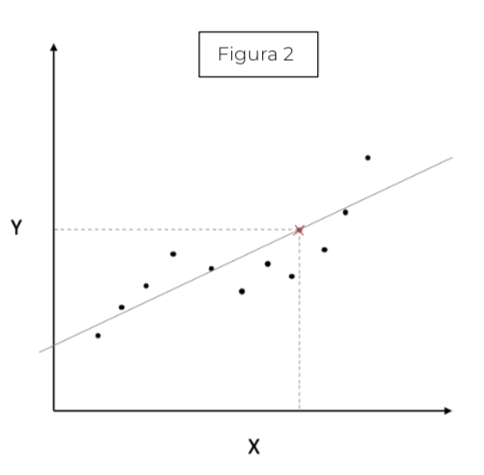
Una vez tenemos claro qué es lo que buscamos en un modelo Machine Learning, ¿qué herramientas tenemos para abordarlo? Pues bien, antes de nada, es preciso recalcar que no es necesario irse a problemas muy complejos, pues una regresión simple en el plano es un modelo capaz de inferir a partir de los datos dados, dónde se situarían los nuevos datos que llegasen (punto gris figura 1). Pero ¿un modelo que se ajuste bien a los datos es un modelo que generaliza bien? Imagínate que ahora los datos tienen otra forma (figura 2) y en vez de ajustar una recta a la nube de puntos
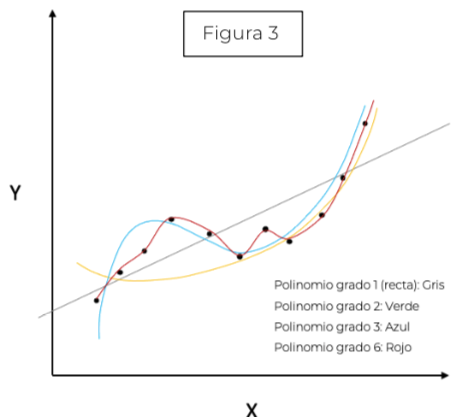
ajustamos una curva, pues suponer que la relación entre las variables es lineal no es suficiente (la recta no es capaz de adaptarse a la naturaleza de los datos) ygenerará un modelo incapaz de hacer buenas predicciones para nuevos datos (figura 2). Por tanto, tendríamos un modelo mal ajustado o dicho de manera más precisa, el modelo sufriría de underfitting (subajuste). Esto es fácil de solucionar aumentando el grado del polinomio (curvar la recta) y, a través de la minimización de ciertas ecuaciones, sería capaz ajustar la curva a la nube de puntos. Si en vez de una recta utilizásemos un polinomio de grado 2 (figura 3) obtendríamos la curva verde, y mejoraríamos nuestro modelo. Y si el grado del polinomio fuese 3 (figura 3) nos daría un mejor resultado. Pero aún no hemos respondido a la pregunta anterior ¿un modelo que se ajuste bien a los datos es un modelo que generaliza bien? Supongamos que seguimos aumentando nuestro grado delpolinomio generando la curva roja (figura 3). Si nos diesen nuevos datos (figura 4) parece que el polinomio de grado 3 sí se ajustaría bien, mientras que el polinomio de grado 6, a pesar de ajustarse correctamente, no generalizari´an bien (figura 5), estaríamos modelando el ruido de los datos (Overfitting).
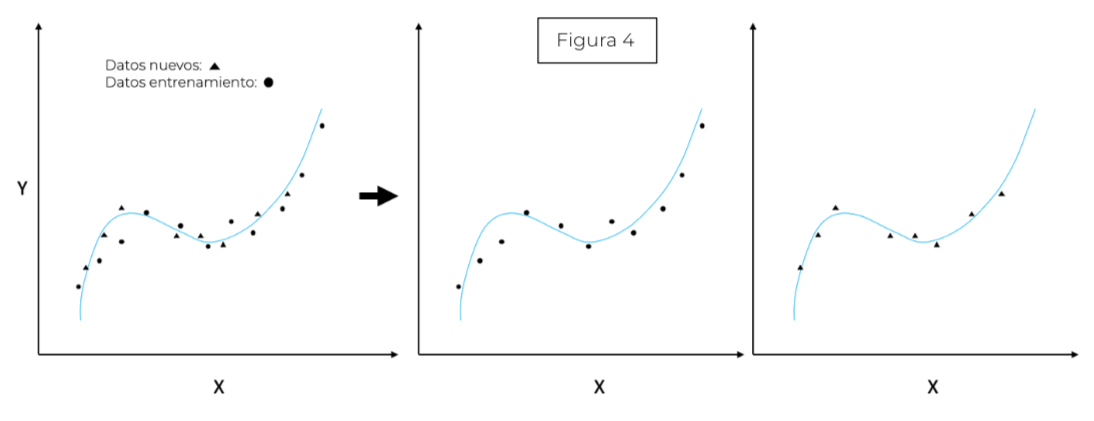
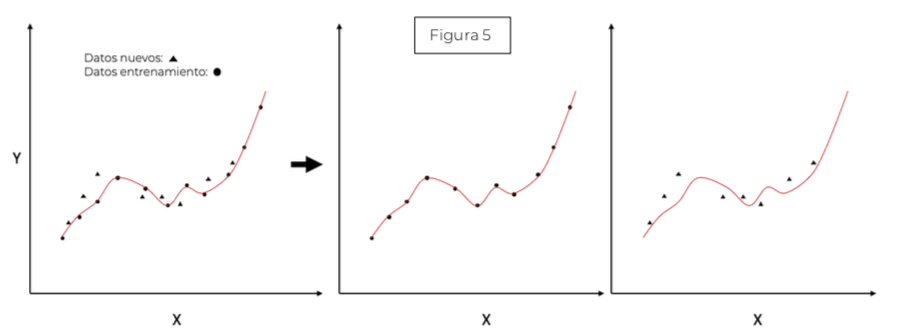
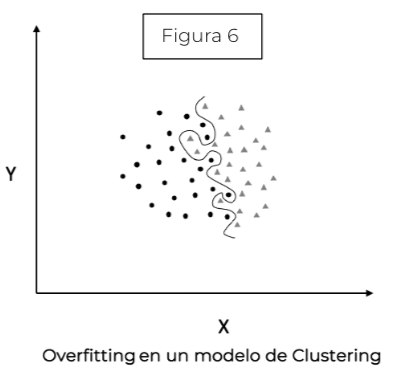 Esto podría aplicarse a problemas más complejos de Machine Learning (figura 6).
Esto podría aplicarse a problemas más complejos de Machine Learning (figura 6).
En conclusión, un modelo simple puede ser demasiado rígido y puede no adaptarse a los datos, generando grandes errores en los datos de entrenamiento (mal ajuste) y grandes errores en los datos nuevos (mala generalización), es decir, underfitting (alumno B). Por el contrario, el modelo puede no cometer errores en los datos de entrenamiento (buen ajuste) pero generar grandes errores en los datos nuevos (mala generalización) y estaremos hablando de un caso de overfitting (alumno C). Entonces, ¿un modelo que se ajuste bien a los datos es un mod elo que generaliza bien? Falso.